Code Like a Pro with AI using GitHub Copilot
data science
AI
GitHub Copilot
R

AI Tutorial: Using Text Embeddings to Label Synthetic Doctor’s Notes Generated with ChatGPT
data science
generative AI
ChatGPT
OpenAI
machine learning



Tidymodels: tidy machine learning in R
R
tidyverse
machine learning
tidymodels
caret
recipes
parsnip
tune
rsample
5 useful R tips from rstudio::conf(2020) - tidy eval, piping, conflicts, bar charts and colors
R
rstudioconf
tidyverse
ggplot2
tidyeval
visualization

Learn to purrr
R
purrr
tidyverse
Transitioning into the tidyverse (part 2)
R
tidyverse
tidyr
purrr
readr
tibbles
lubridate
forcats
stringr
Using the recipes package for easy pre-processing
R
workflow
machine learning
A quick guide to developing a reproducible and consistent data science workflow
data science
workflow
reproducibility
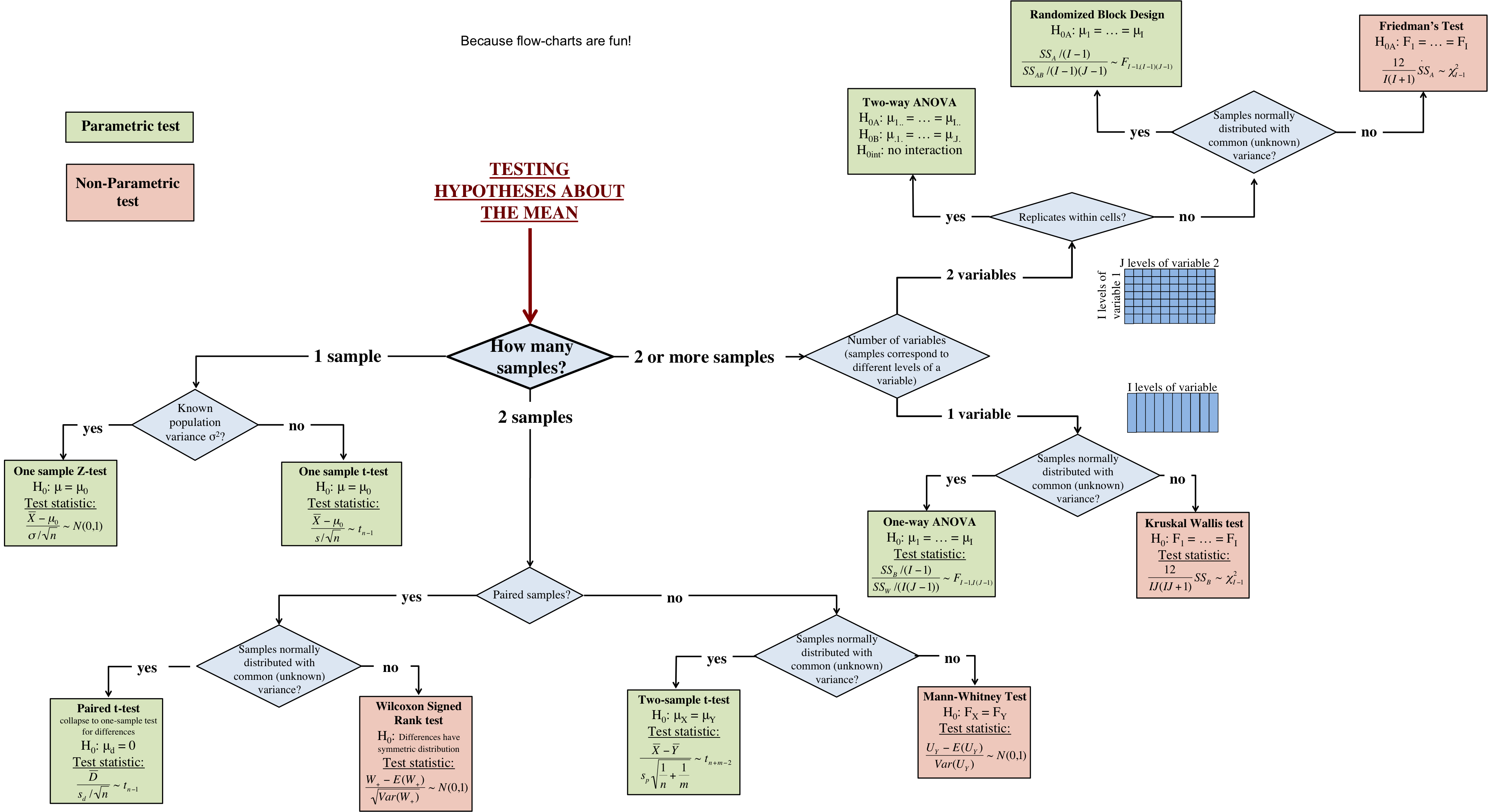
Which hypothesis test should I use? A flowchart
statistics
hypothesis testing
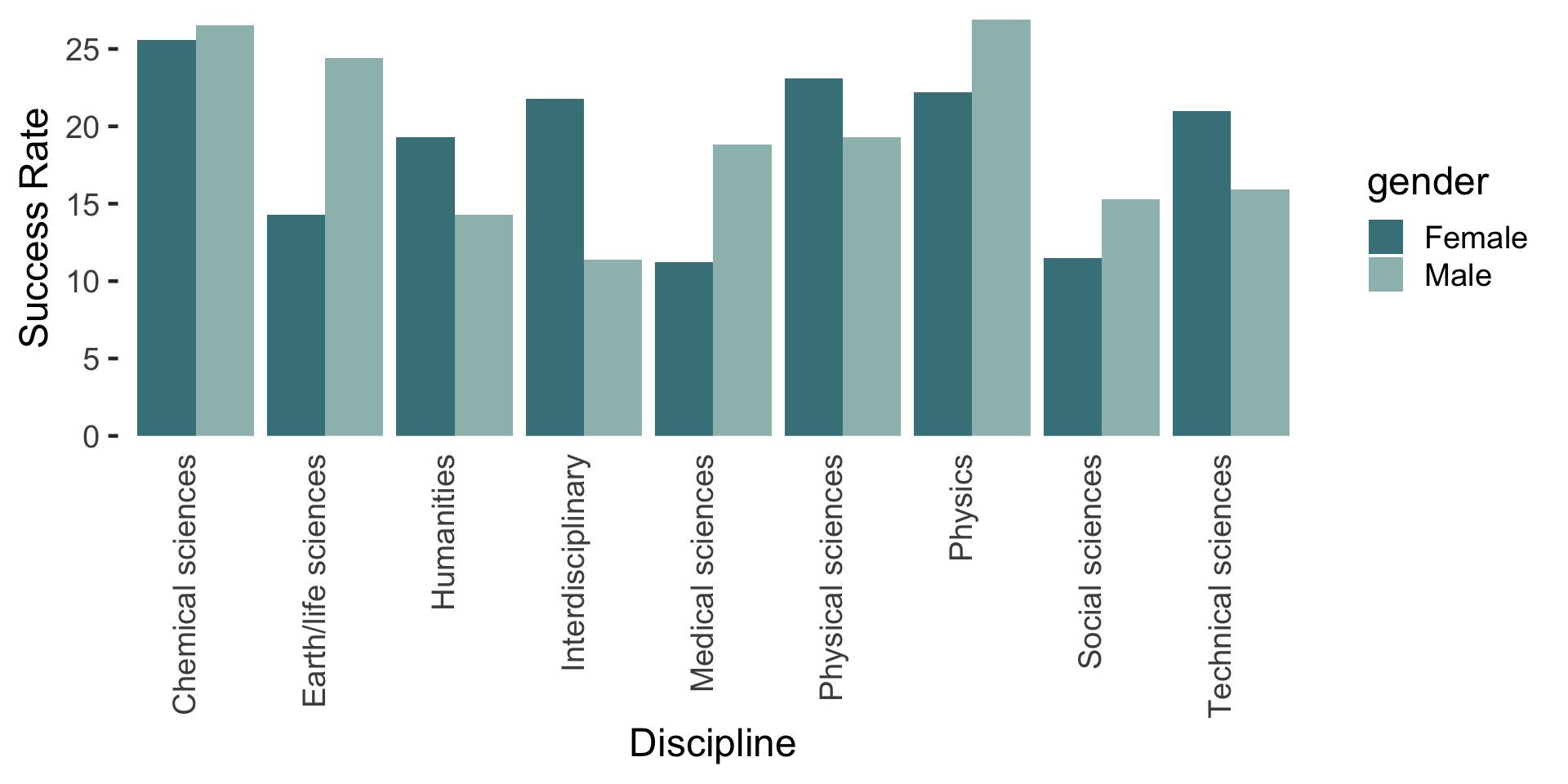
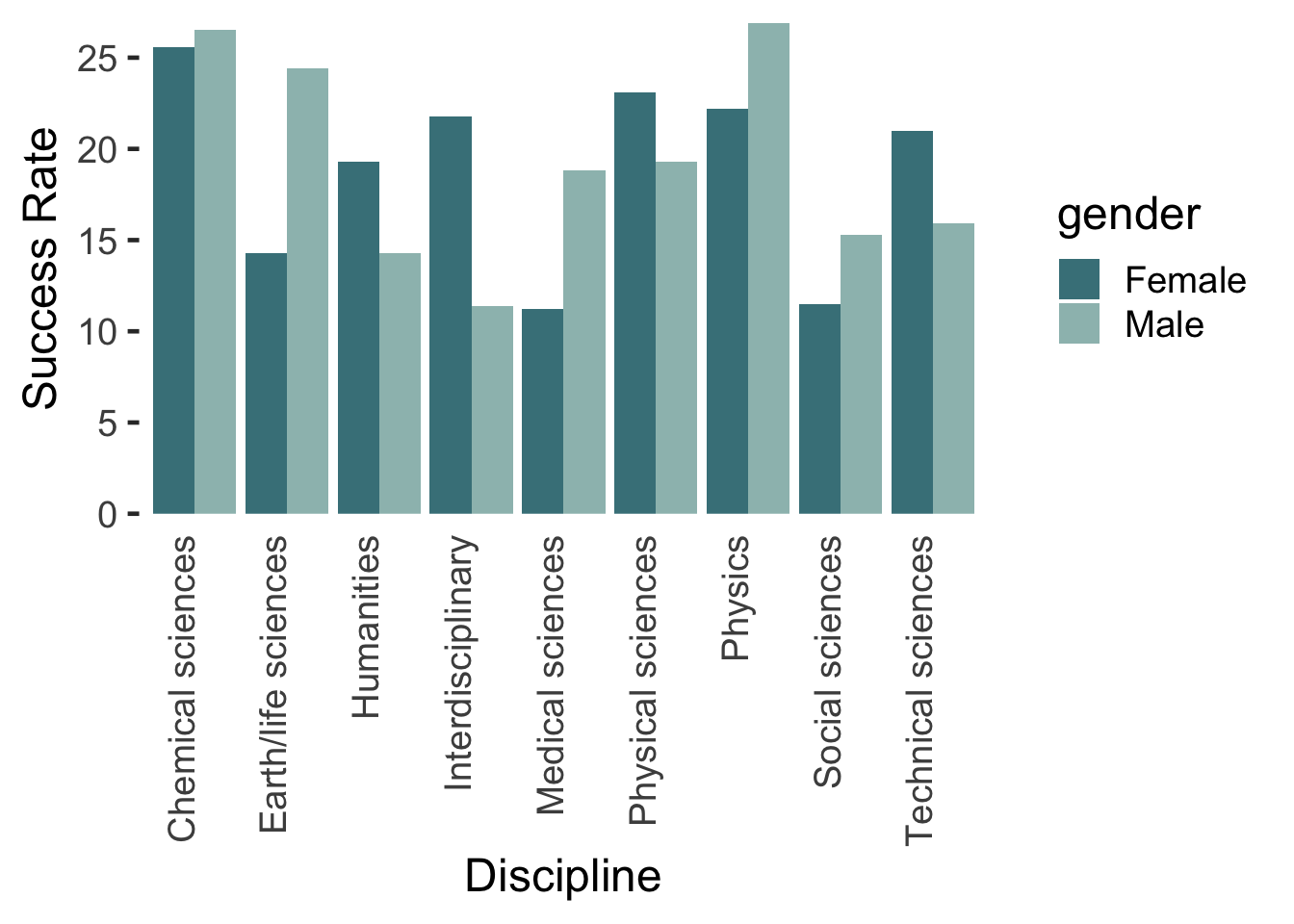
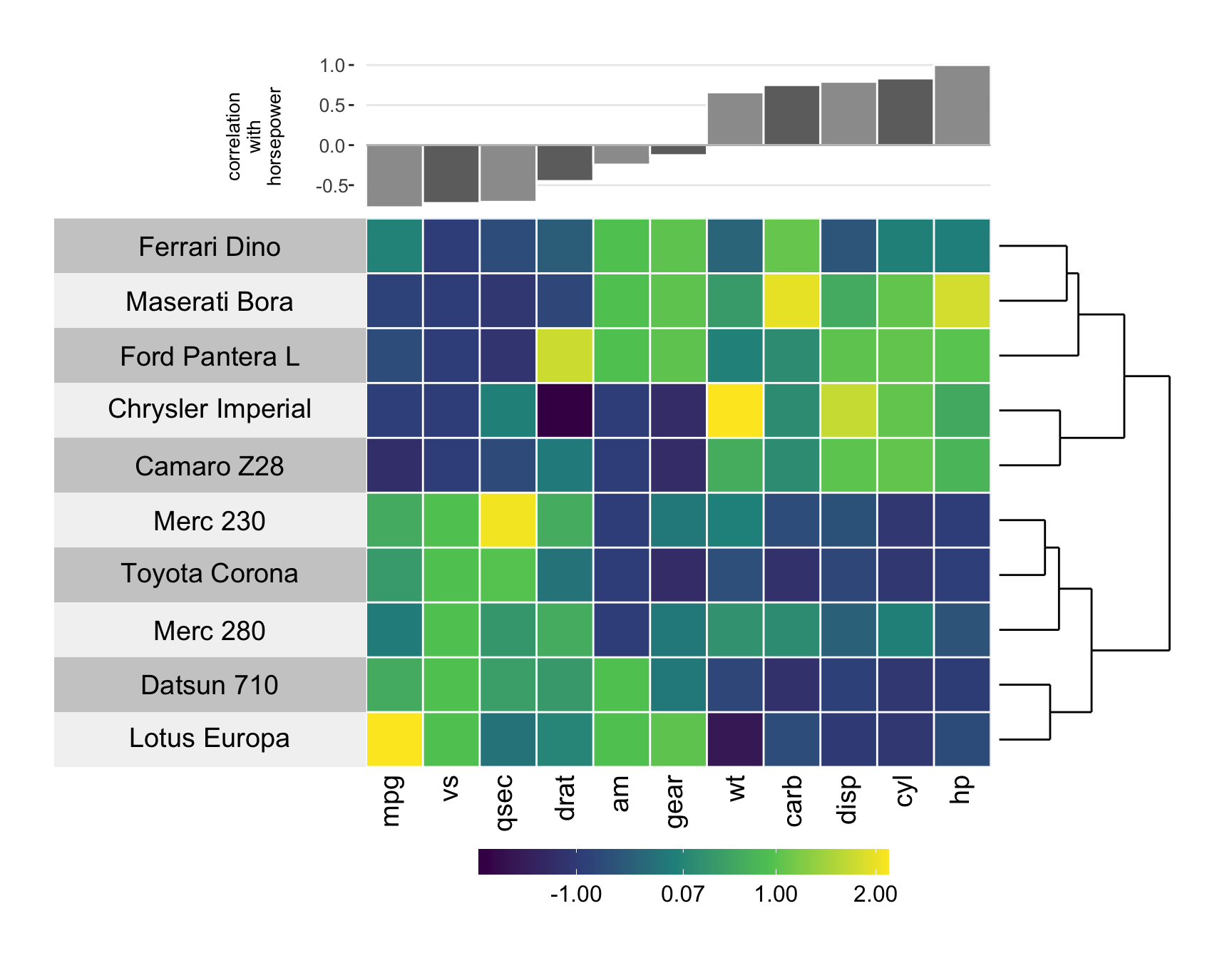
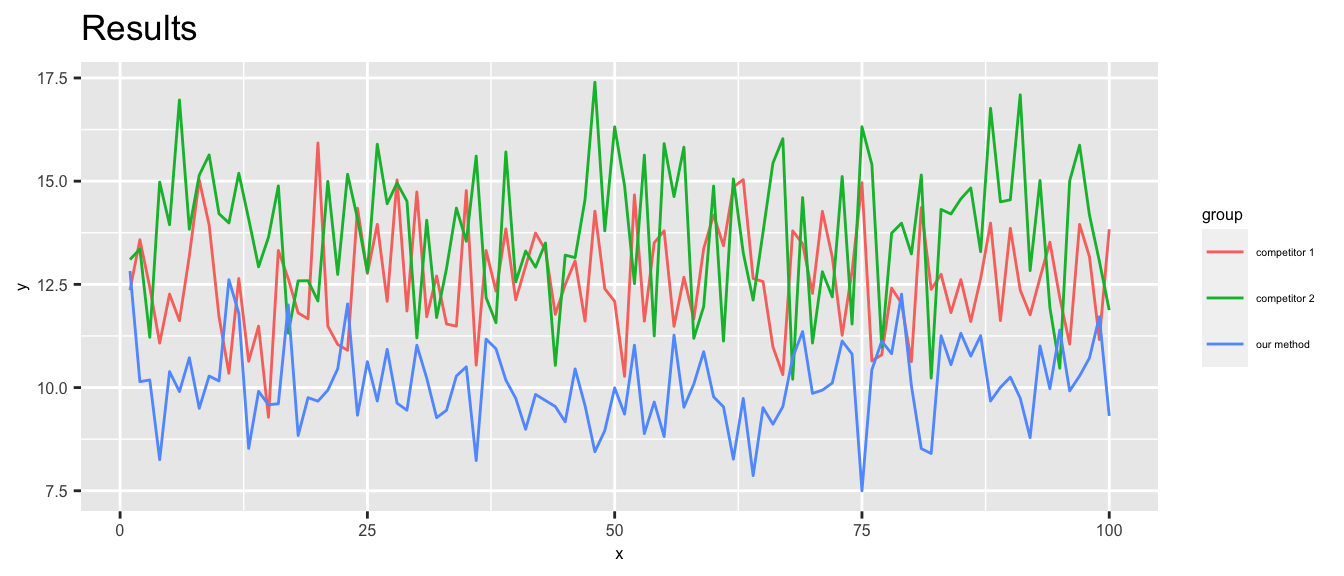
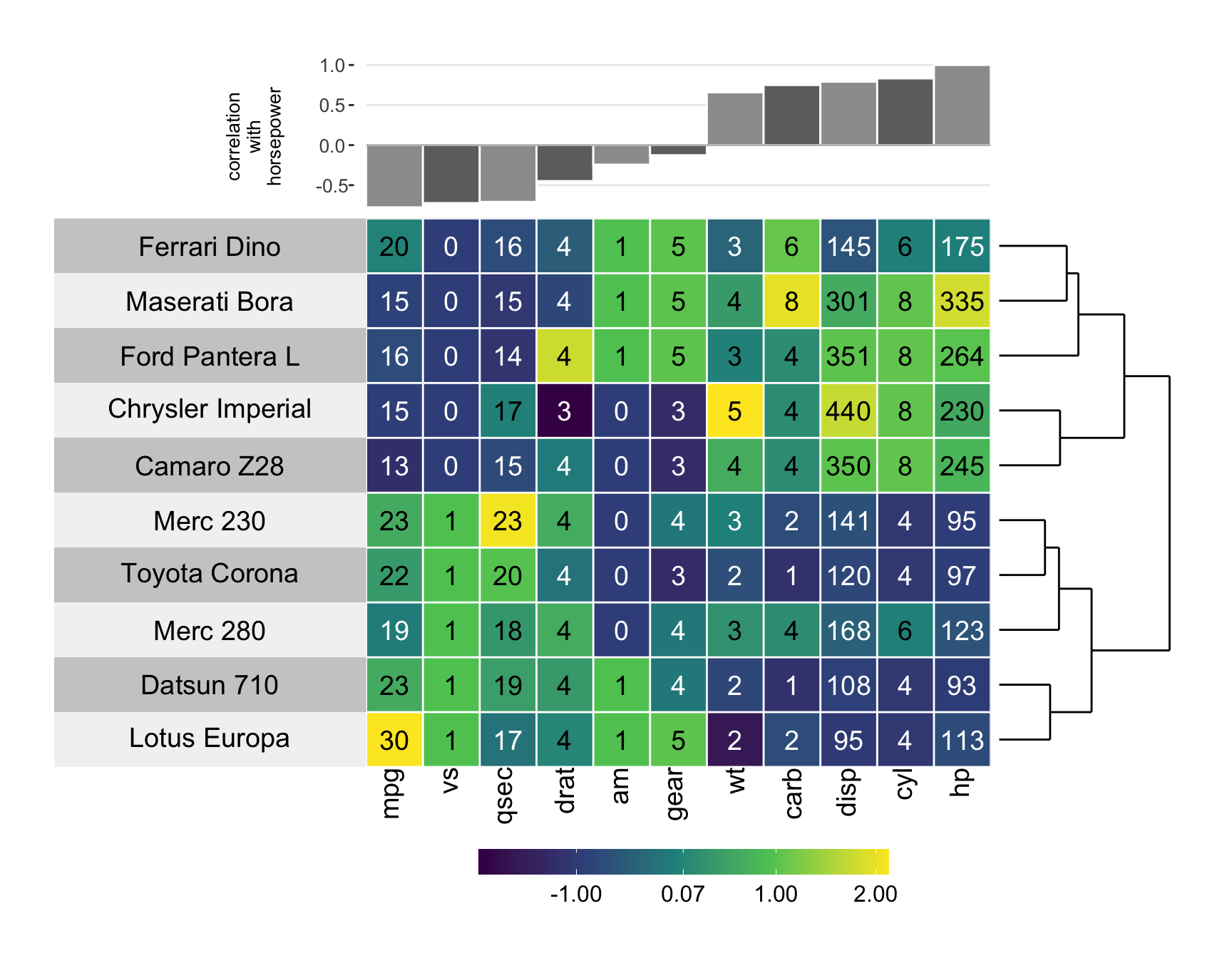
Alternatives to grouped bar charts
R
visualization
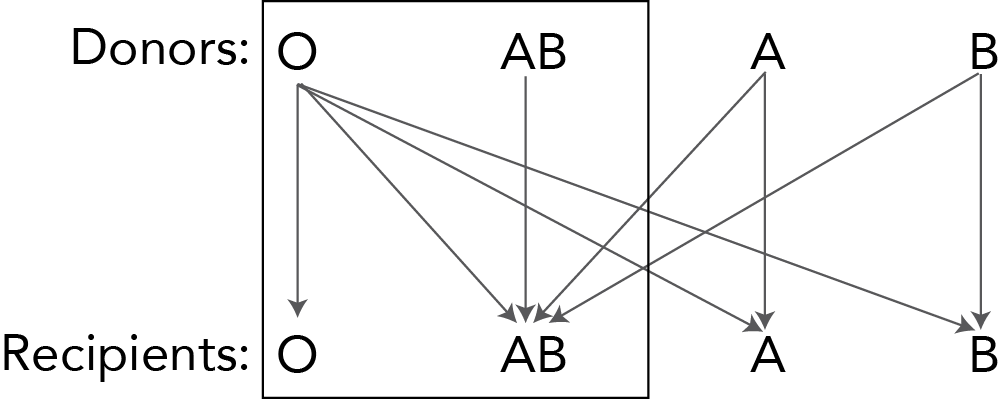
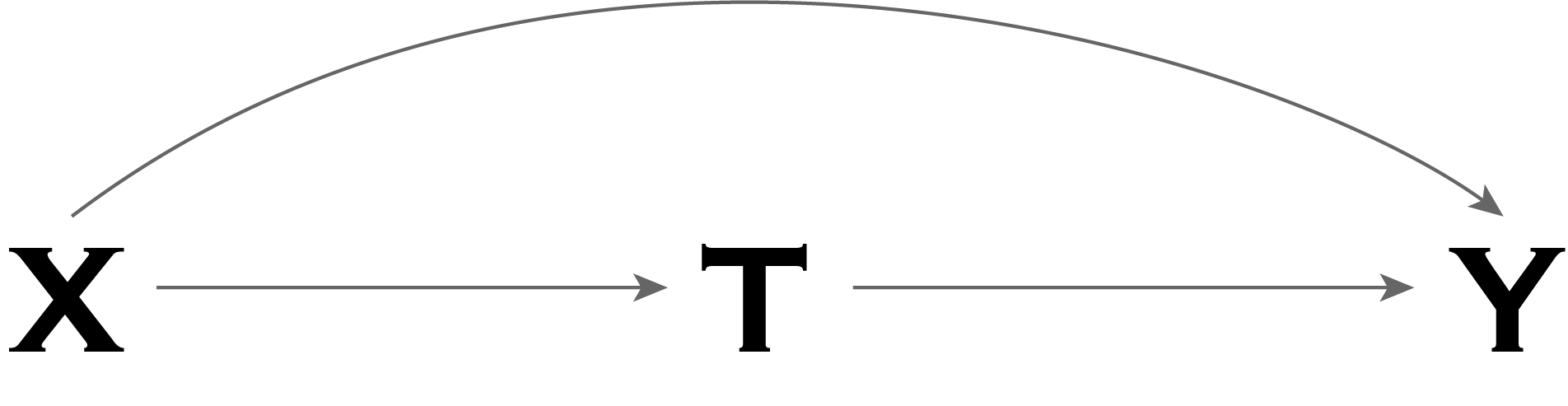
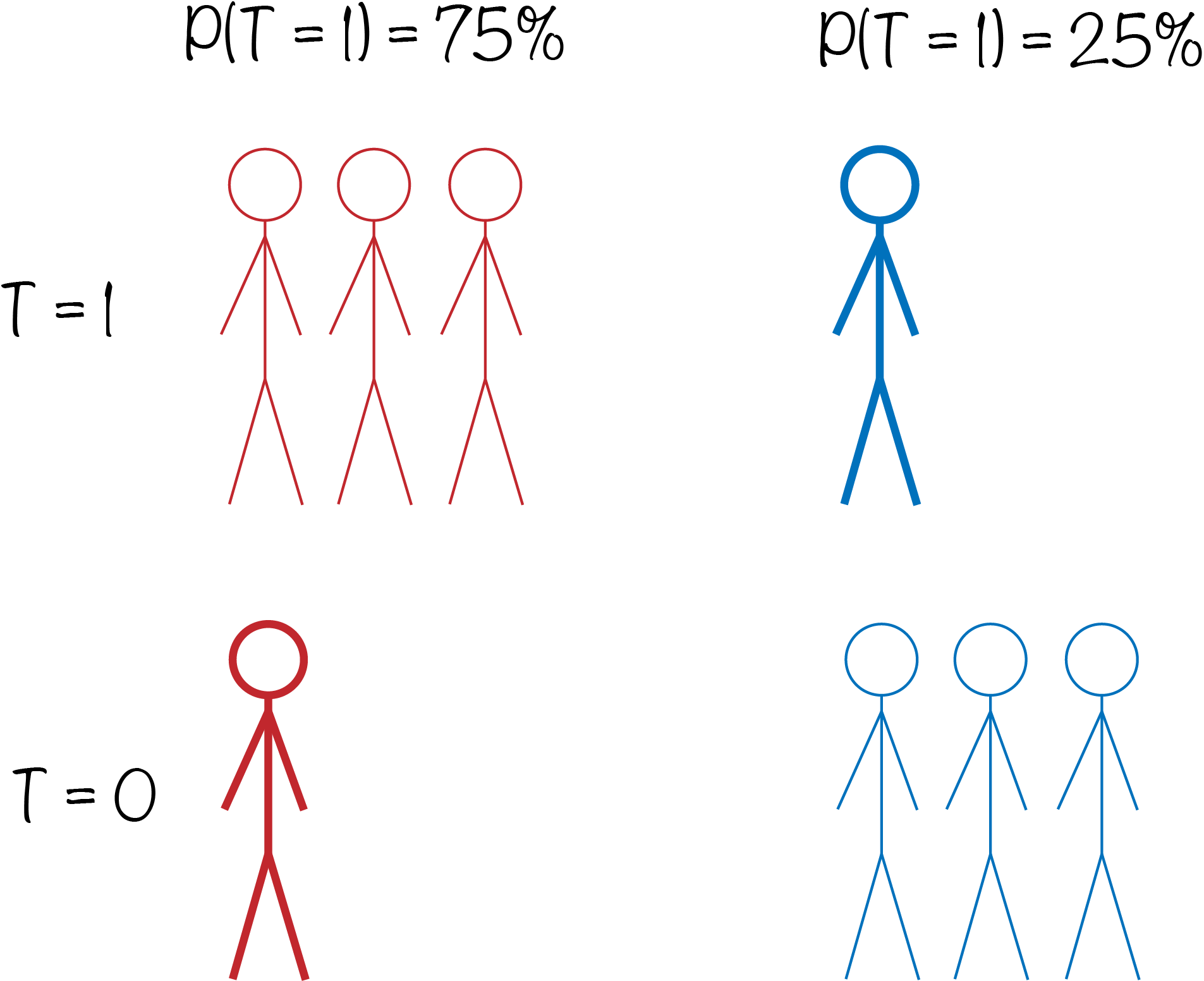
Understanding Instrumental Variables
causal inference
statistics

A basic tutorial of caret: the machine learning package in R
R
machine learning
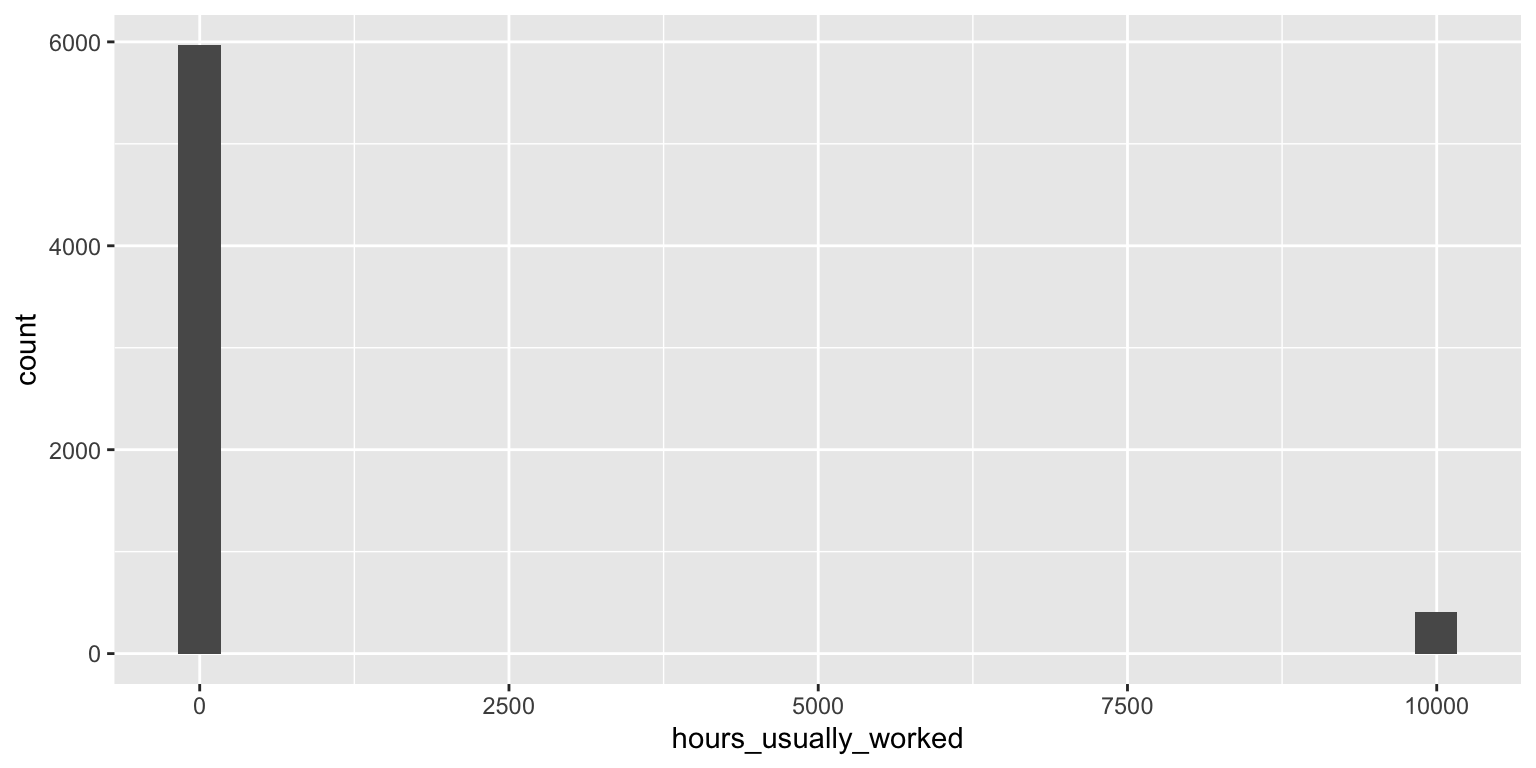
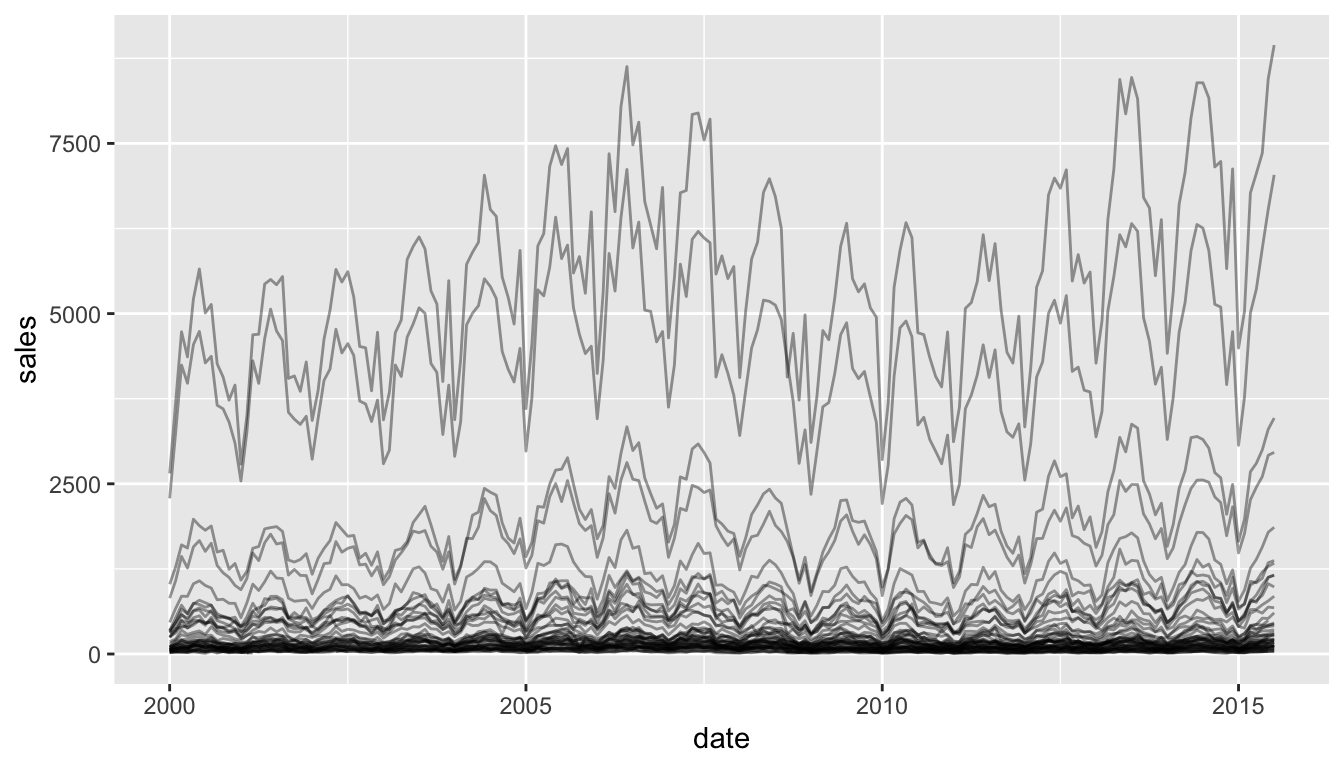
Interactive visualization in R
visualization
R
interactivity

Docathon: A Week of Doumentation
documentation
R
communication

No matching items